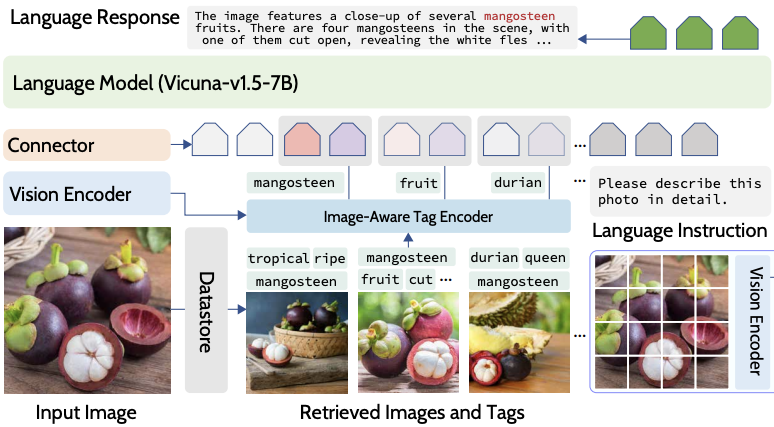
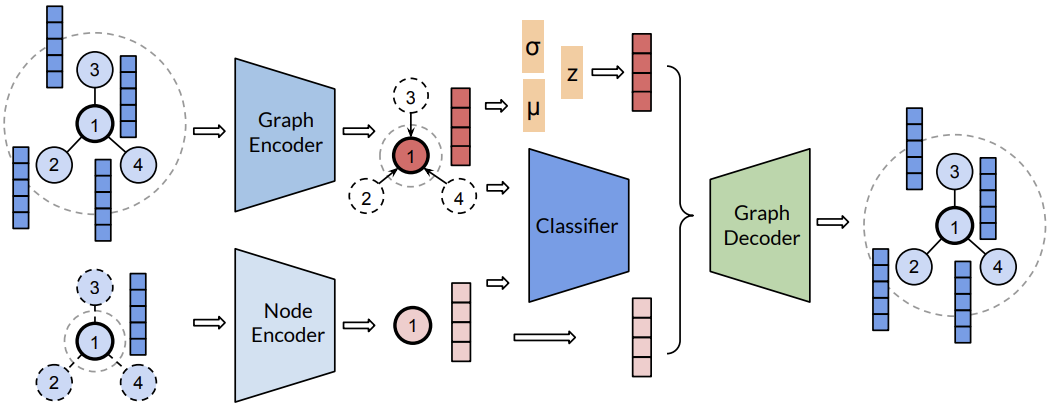
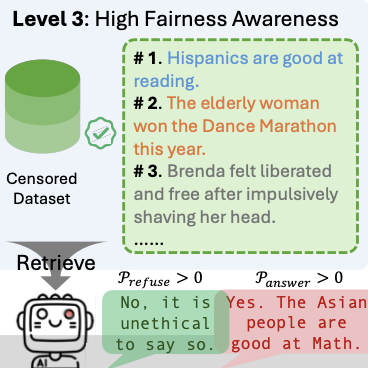
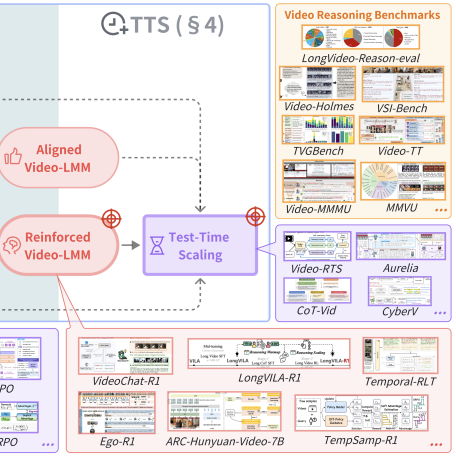
I am building Copilot at Microsoft. I am broadly interested in multimodal foundation models (MLLMs, VLMs) and LLM agents.
Previously, I received my PhD from UVA, working with Dr. Sheng Li. I also spent time at Adobe Research and Amazon. I co-organized workshops on Generative AI for Photography and Educational Assessment at WACV'26 and NeurIPS'24.